数据导入
在数据库中,用户经常使用 insert 语句插入数据。但在流处理中,数据连续不断地从上有系统导入,显然 insert 语句无法满足需求。RisingWave 允许用户直接创建 table 与 source 来导入上游数据。当上游系统有新的数据进入时,RisingWave 便会直接消费数据并进行增量计算。
RisingWave 常见的上游数据源系统包括:
消息队列,如 Apache Kafka、Apache Pulsar、Redpanda 等等;
操作型数据库,如 MySQL、PostgreSQL、MongoDB 等等;
存储系统,如 AWS S3 等等。
读者可以查阅官方文档以了解全部支持的数据源。
table 与 source
在 RisingWave 中,用户可以使用以下语句创建 table 或 source,从而跟上游系统建立连接。
CREATE {TABLE | SOURCE} source_or_table_name
[optional_schema_definition]
WITH (
connector='kafka',
connector_parameter='value', ...
)
...
创建好 table 或 source 之后,RisingWave 便会源源不断地从上游系统拉数据。
| 功能 | table | source |
|---|---|---|
| 支持持久化数据 | 是 | 否 |
| 支持定义主键 | 是 | 否 |
| 支持追加数据 | 是 | 是 |
| 支持修改删除数据 | 是,但需定义主键 | 否 |
table 与 source 有一个非常本质的区别:table 会持久化消费的数据,而 source 不会。
比如说,上游如果输入了5条记录:AA BB CC DD EE,如果使用 table,则这5条记录会被持久化到 RisingWave 内部;如果使用 source,则这些记录不会被持久化。
下图展示了在 RisingWave 中创建 table 时的逻辑。
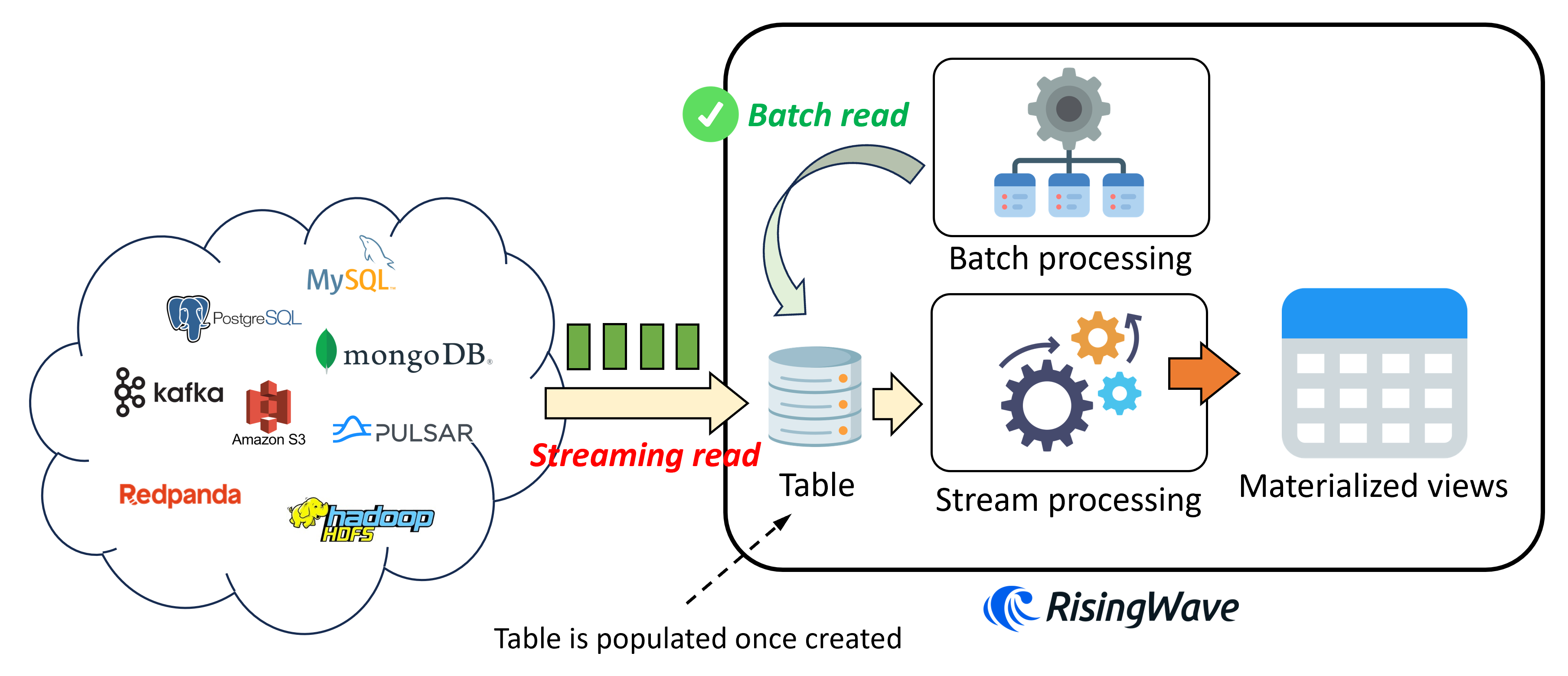
这边有几个要点值得注意:
- 当用户发送
create table请求之后,相应的表会立刻被创建并填入数据; - 当用户在创建好的
table上建立物化视图时,RisingWave 会从table里开始读数据,进行流计算; - RisingWave 的批处理引擎支持直接批量读取
table。用户可以直接发送随机查询,查看table内部的数据。
使用 table 持久化记录带来的很大好处便是能够加速查询。 毕竟数据如果在同一个系统中,查询自然会高效非常多。当然缺点就是占存储。另一个好处便是可以消费数据变更。也就是说,上游系统如果删除或者更新了一条记录,那么这条操作会被 RisingWave 消费,从而修改流计算的结果。而 source 只支持追加记录,无法处理数据变更。当然,想让 table 接受数据变更,必须在 table 上指定主键。
下图展示了在 RisingWave 中创建 source 时的逻辑。
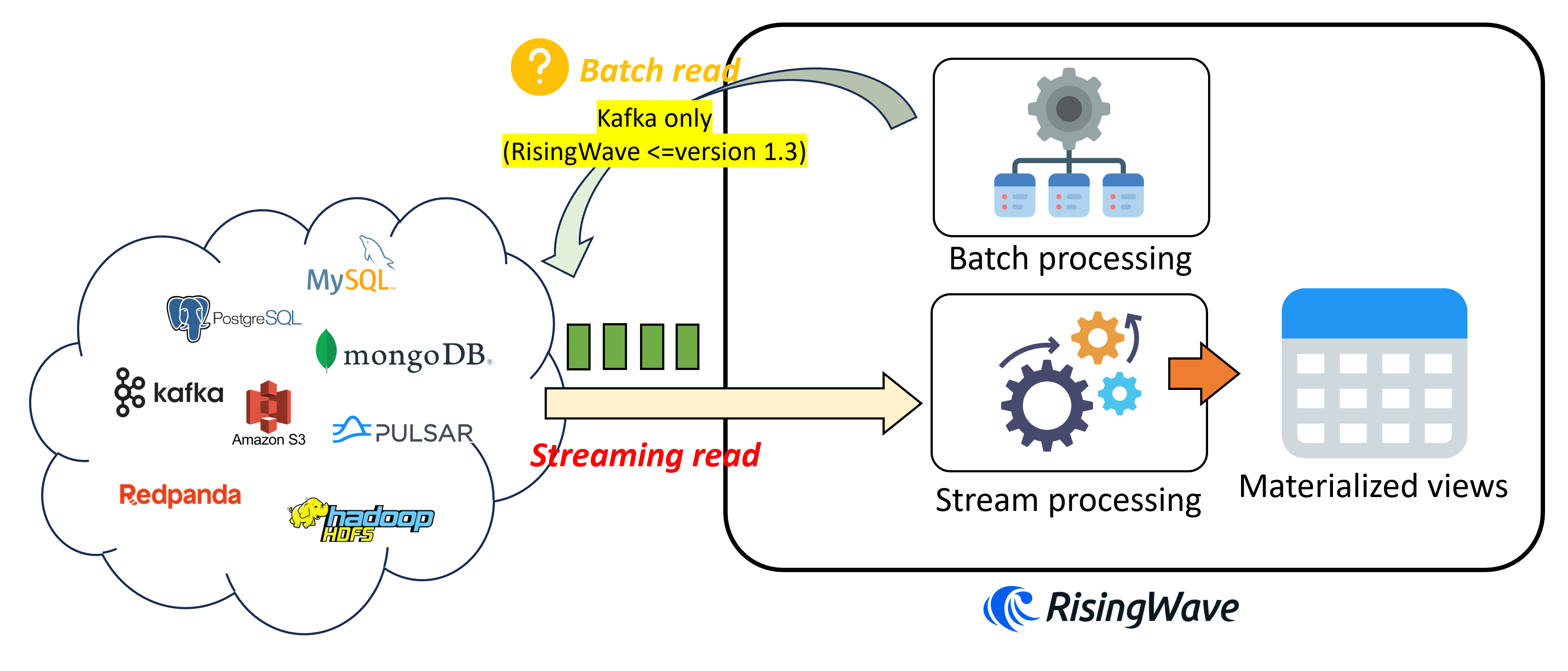
几个值得注意的点:
- 当用户发送
create source请求之后,并不会创建任何物理对象,也不会立刻从source里读取数据; - 只有当用户在该
source上创建物化视图或者sink时,才会从source里开始读取数据; - RisingWave 的批处理引擎在 1.3 版本(及之前)仅支持从 Kafka 中批量读取
source。 当用户发送随机查询访问source时,会报异常。
一些用户不希望将数据持久化到 RisingWave 中。而如果数据不持久化到 RisingWave 中,则 RisingWave 无法获得数据的所有权。如果支持随机查询 source 数据,即是要求 RisingWave 直接读取存储在上游系统中的数据。这种跨系统数据读取很容易出现数据不一致问题,因为 RisingWave 无法判断上游系统是否还有其他用户正在进行写操作。此外,频繁进行跨系统访问会造成系统性能大幅下降。为了保证一致性与性能, RisingWave 从初始设计上不支持随机查询 source。
当然正如大家所看到的,一些数据库,如 PostgreSQL (需插件),支持对外部数据源进行随机访问。根据用户要求,RisingWave 首先支持了对 Kafka 的随机查询功能。支持对更多系统的随机查询可能会被加入到开发路线图中。如果大家对这一功能有需求,欢迎提出与我们讨论。
代码示例
我们现在快速验证一下 RisingWave 导入数据的能力。由于 RisingWave 试玩模式不支持数据库 CDC(需要至少使用 Docker 部署模式),所以大家选用 Apache Kafka 做上游消息源系比较合适。如果没有 Kafka,也没有问题,我们直接选用 RisingWave 自带的 datagen 工具来进行模拟。
导入数据
我们分别创建一个 table 与一个 source,并使用 datagen 工具导入数据:
CREATE TABLE t1 (v1 int, v2 int)
WITH (
connector = 'datagen',
fields.v1.kind = 'sequence',
fields.v1.start = '1',
fields.v2.kind = 'random',
fields.v2.min = '-10',
fields.v2.max = '10',
fields.v2.seed = '1',
datagen.rows.per.second = '10'
) ROW FORMAT JSON;
CREATE SOURCE s1 (w1 int, w2 int)
WITH (
connector = 'datagen',
fields.w1.kind = 'sequence',
fields.w1.start = '1',
fields.w2.kind = 'random',
fields.w2.min = '-10',
fields.w2.max = '10',
fields.w2.seed = '1',
datagen.rows.per.second = '10'
) ROW FORMAT JSON;
我们来验证一下创建是否成功:
show tables;
得到:
Name
------
t1
(1 row)
show sources;
得到:
Name
------
s1
(1 row)
注意如果我们用 PostgreSQL 的快捷命令 \d 的话,会发现只能看到 t1,看不到 s1。这是因为 source 并非 PostgreSQL 所定义的关系(relations)。为了保证与 PostgreSQL 的各类工具兼容,RisingWave 不将 source 显示为关系。
在创建 t1 与 s1 一段时间后,我们用 select 语句查询一下 t1 与 s1:
select count(*) from t1;
得到结果(具体得到的数字可能完全不一样):
count
-------
8780
(1 row)
select count(*) from s1;
得到结果:
ERROR: QueryError: Scheduler error: Unsupported to query directly from this source
这个结果是符合预期的。因为在 RisingWave 中,用户不能对除 Kafka 以外的 source 进行查询。
进行流计算
接着我们开始创建物化视图进行流计算。我们同时对 t1 与 s1 构建物化视图:
create materialized view mv_t1 as select count(*) from t1;
create materialized view mv_s1 as select count(*) from s1;
使用:
select * from mv_t1;
得到结果(具体得到的数字可能完全不一样):
count
-------
12590
(1 row)
使用:
select * from mv_s1;
得到结果(具体得到的数字可能完全不一样):
count
-------
320
(1 row)
大家可能会感到有些意外:明明 mv_t1 与 mv_s1 在几乎同一时间被创建,且 t1 与 s1 的数据差不多,为什么结果有很大区别?
这是因为当 table 被创建时,RisingWave 就已经开始从上游消费数据,并将数据持久化到系统内部。如果在 table 上在任何时间创建物化视图,那么新建的物化视图便会从 table 最老的数据开始读起,进行流式计算。
而当 source 被创建时,RisingWave 并不会立刻从上游消费数据。只有当任意一个物化视图在该 source 上创建之后,RisingWave 才开始从 source 对应的上游消费数据。
回到以上例子。当 t1 被创建的瞬间,RisingWave 已经从上游(也就是 t1 所对应的 datagen)消费数据,并将数据持久化在 t1 内。当创建 mv_t1 时,RisingWave 会先读取 t1 已经保存下来的数据,再继续消费 datagen 的数据。而当 s1 被创建时,RisingWave 并不会立刻消费数据。直到 mv_s1 被创建的瞬间,RisingWave 才开始消费上游数据。因此我们看到了不同的结果。
继续阅读
连接器 - Source:详细了解不同上游数据源系统的具体连接方法和可配置项