快速入门
本文的目的是让大家能够在 10分钟之内 了解 RisingWave 流数据库是什么。
本教程并非正式官方教程,并且不保证与官方文档内容同步(本教程写作时基于2023年10月发布的 RisingWave 1.3.0版本)。本教程的目的仅是让大家快速学习 RisingWave 流数据库。具体内容还请读者以官方文档为准。
本教程仍在持续开发中。最新更新日期为: 2023年11月17日。 欢迎对 RisingWave、流处理、数据库或是数据工程感兴趣的朋友们提出宝贵的建议!
什么是 RisingWave
RisingWave 是一款基于 Apache 2.0 协议开源的分布式流数据库。RisingWave 让用户使用操作传统数据库的方式来处理流数据。通过创建实时物化视图,RisingWave 可以让用户轻松编写流计算逻辑,并通过访问物化视图来对流计算结果进行及时、一致的查询。
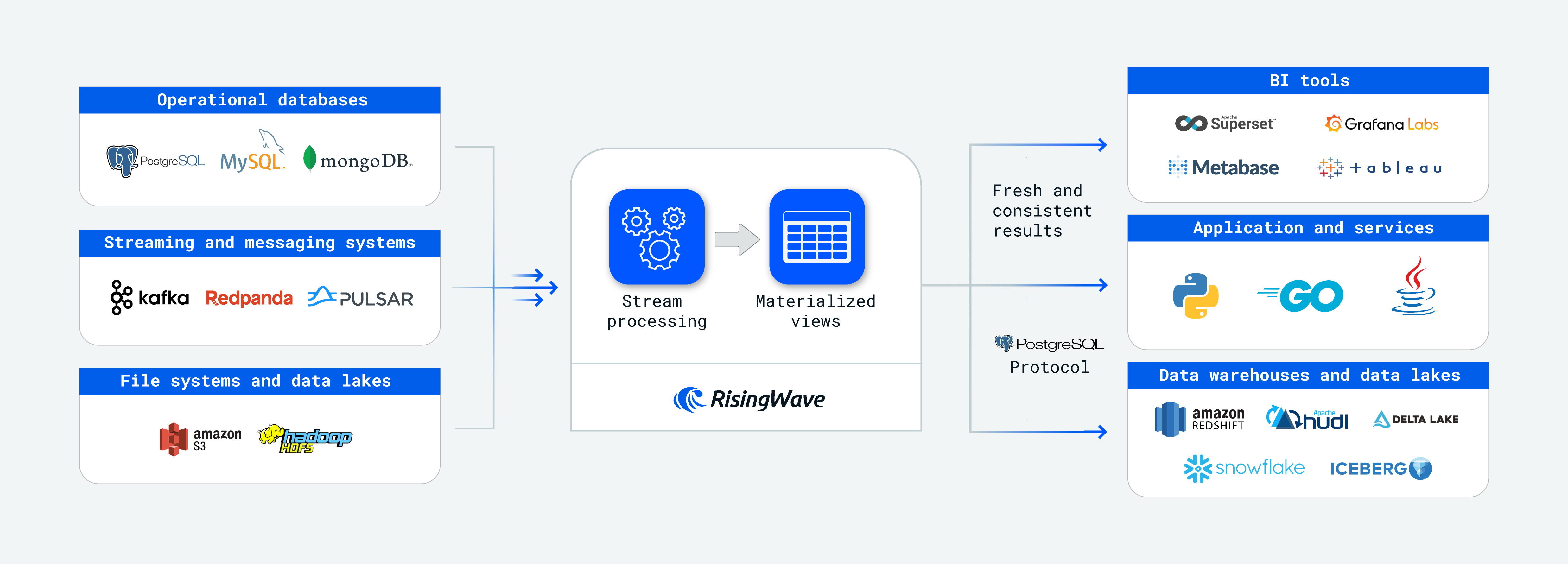
用户可以使用 RisingWave 来进行:
- 实时物化视图支持(即流计算);
- 数据存储;
- 随机查询(尤其是点查)。
用户不应该使用 RisingWave 来进行:
- 事务处理;
- 频繁的涉及到全表扫描的复杂查询。
实时物化视图与流计算
实时物化视图是 RisingWave 的核心概念。在 RisingWave 中,物化视图拥有一致性、持久化、可被高并发查询等特性,并通过连续不断的增量流计算来维护的。用户通过定义物化视图来表达流计算逻辑,并通过查询物化视图来对流计算结果进行一致性访问。
RisingWave 允许用户创建级联物化视图(cascading materialized view),也就是说,用户可以在物化视图上再定义物化视图。同时,所有物化视图均可被用户直接访问。这一能力大大降低了用户开发流计算应用的复杂度。
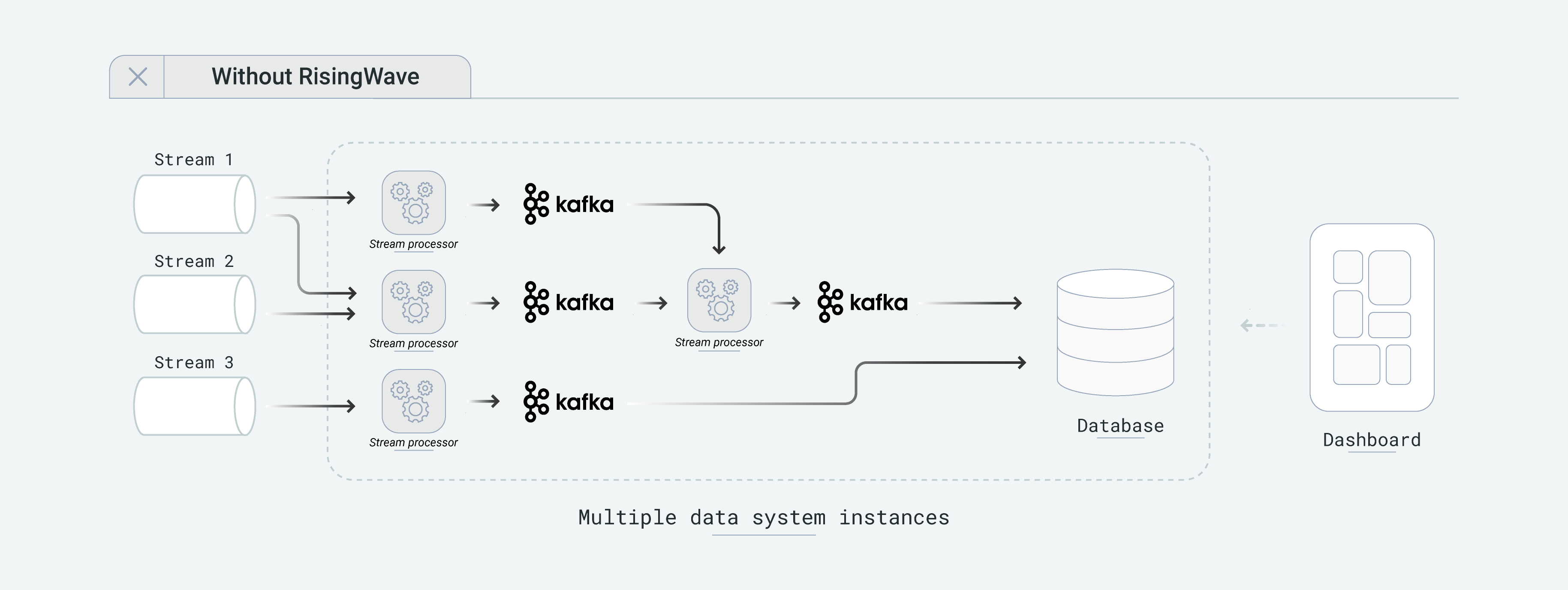
当使用传统流计算引擎(如 Apache Flink、Apache Spark Streaming 等)进行应用开发时,用户往往需要通过拼装流计算引擎与消息队列来表达复杂逻辑。为了对结果进行查询,用户又不得不将流处理结果导出到专门的下游数据库中,并在下游数据库中进行查询。整个架构复杂、运维成本高,且用户需要对跨系统间计算结果一致性负责。
下图展示了使用传统流处理引擎构建应用时的情况。开发者需要运维多个系统,并管理系统之间的依赖性一致性关系。
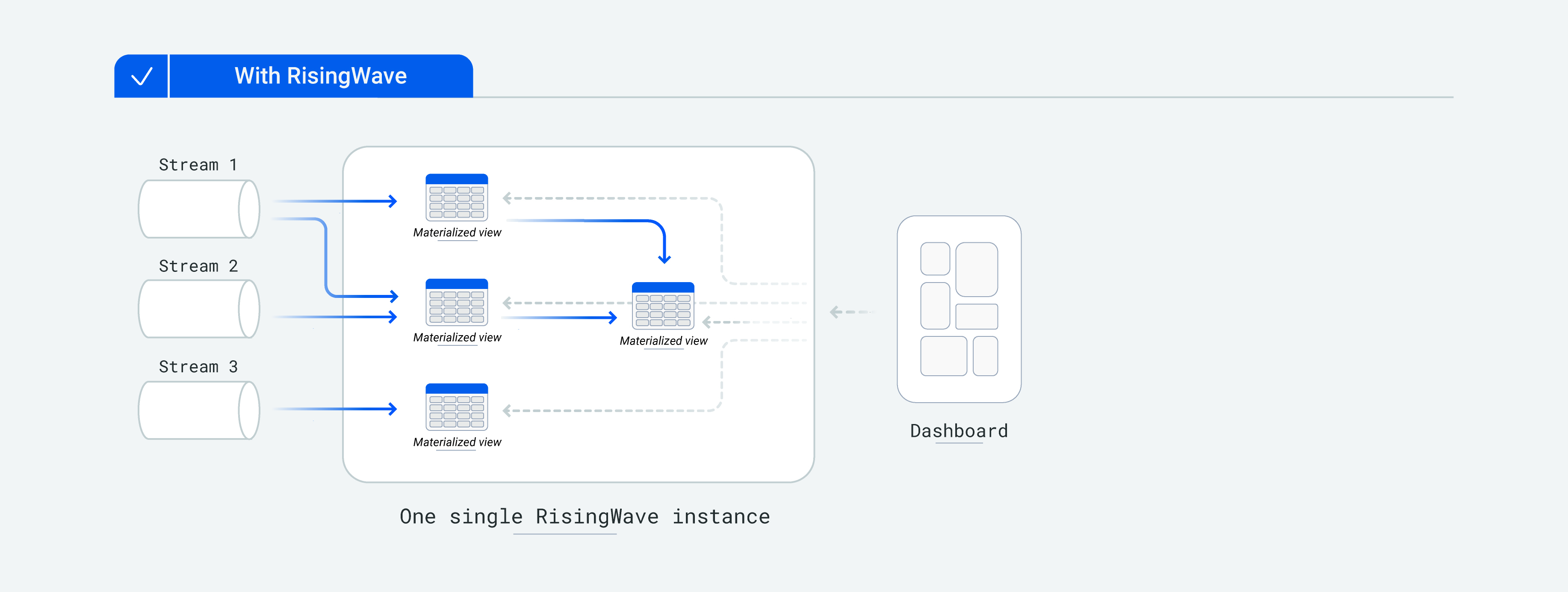
而当使用 RisingWave 时,用户只需关注如何构建物化视图,并且可以通过将复杂逻辑拆分成多个级联物化视图来降低开发复杂度。RisingWave 保证物化视图一致性、持久化、可被高并发查询。用户只需运维一套 RisingWave 集群,RisingWave 负责保证不同物化视图之间的一致性。
下图展示了使用 RisingWave 流数据库开发应用的情况。开发者只需运维一个系统,并无需考虑任何不同系统组件之间的关系。
为什么选用 RisingWave 做物化视图?
如果你拥有使用数据库的经验,应该在各类数据库中均遇到过物化视图。传统数据库如 PostgreSQL,数据仓库如 Redshift 与 Snowflake, 实时分析数据库如 ClickHouse 与 Apache Doris 等,都拥有物化视图能力。但 RisingWave 的物化视图相较其他数据库的物化视图有以下几个重要特征:
实时性
不少数据库使用异步方式更新物化视图,或者要求用户手动更新物化视图。而 RisingWave 上的物化视图使用同步方式更新,用户永远可以查询到最新鲜的结果。即便是数据有更改删除、需要处理带有 join、windowing 等复杂查询,RisingWave 也能够进行高效同步处理,保证物化视图新鲜度。
一致性
一些数据库仅提供最终一致性的物化视图,也就是说,用户看到的物化视图上的结果只是近似结果,或者是带有错误的结果。尤其是当用户创建多个物化视图时,由于每个物化视图刷新策略不同,用户很难在跨物化视图之间看到一致性结果。而 RisingWave 的物化视图是一致性的,哪怕访问多个物化视图,用户看到的结果永远是正确的,而不会看到不一致的结果。
高可用
RisingWave 持久化物化视图,并设置高频率检查点保证快速故障恢复。当搭载 RisingWave 的物理节点宕机时, RisingWave 可以实现秒级恢复,并且在秒级将计算结果更新至最新状态。
高并发
RisingWave 支持高并发随机查询。由于 RisingWave 将数据实时持久化在远端对象存储中,用户可以根据负载动态配置查询节点数量,更高效的支撑业务需求。
流处理语义
在流计算领域里,用户可以使用高阶语法,如时间窗口、水位线等,对数据流进行处理。而传统数据库并不带有这些语义,因此往往用户需要依赖外部系统处理这些语义。RisingWave 是流处理系统,自带各种复杂流处理语义,并可以让用户用 SQL 语句来进行操作。
资源隔离
物化视图是连续不断的流计算,会占用到大量计算资源。为避免物化视图计算干扰到其他计算,一些用户会将 OLTP 或者 OLAP 数据库中的物化视图功能转移到 RisingWave 中处理,从而实现资源隔离。
为什么选用 RisingWave 做流计算?
如果你拥有使用流处理系统的经验,应该不会对 Apache Flink、Apache Spark Streaming、KsqlDB 等开源流处理系统感到陌生。那为什么我们需要使用 RisingWave?
除了能够大幅降低开发流计算应用的复杂度之外,对比于其他流处理系统,RisingWave 着重发力在两大方面:易用性与成本效率。简单来说:
- RisingWave 为用户带来了 PostgreSQL 般的体验来进行流处理,大幅降低使用流计算技术的门槛;
- RisingWave 实现了类似于 Snowflake 的存算分离架构,从而实现计算与存储成本的大幅降低。
从易用性角度,RisingWave 有以下几大特性:
上手简单
现有流处理系统几乎都有很陡峭的学习曲线,不光入门难,在入门之后学习核心概念、使用进阶功能也很难。不少用户在入坑流处理系统之后,被各种底层概念搞得晕头转向,很难掌握各种进阶技巧,如 window、watermark、join 等等,很难真正用好流计算。
RisingWave 提供与 PostgreSQL 兼容的 SQL 接口,并通过 Python、Java 等语言的 UDF 来提升整体表达能力。更重要的是,RisingWave 对底层细节进行了高层封装,让用户无需感知底层实现。
开发简单
目前常用的流处理系统不带存储。也就是说,流计算发生在流处理系统内部,而计算结果需要被导出到其他系统中。也就是说,如果用户进行流计算,那么数据输入在外部系统,数据输出也在外部系统,只有计算是在流处理系统进行的。可想而知结果验证非常不方便。更重要的是,现有流处理系统每个任务(job)独立运行,无法直接创建任务消费其他任务的结果。这导致每个任务的逻辑可能会非常复杂,难以调试,也难以验证正确性。
RisingWave 是流数据库,自带存储。流计算结果以物化视图形式持久化下来。也就是说,计算过程与计算结果均在 RisingWave 内部。这使得用户可以轻易验证程序正确性。另外,用户可以在物化视图上叠加构建物化视图,也就是说,用户可以将复杂流计算程序拆解成多个物化视图,让程序编写与结果验证变得非常简单。
集成简单
大部分现有流处理系统都开发于大数据时代,与各类大数据系统都有很好的集成。而随着云时代的到来,各类开源或闭源系统、工具纷纷涌现出来。集成各类新兴系统所需工程量巨大,维护极其复杂。
RisingWave 与 PostgreSQL 协议兼容,也就是说,RisingWave 可以与大部分和 PostgreSQL 有集成的系统、工具能直接连接,充分享受了 PostgreSQL 生态的丰富性。
从成本效率角度,RisingWave 有以下几大特性:
复杂查询高效
在进行复杂流计算,如 window、join 等时,不少系统会出现性能暴跌甚至崩溃的情况。这是因为在这些系统中,状态保存在本地计算实例,只要状态过大,则会导致性能与稳定性问题。例如,当用户希望使用这些系统 join 多个(比如 5-10 个)数据流时,往往会发现系统效率低下,甚至直接无法运行,更不用提 join 更多流的情况。
RisingWave 采用的存算分离架构使计算状态永远持久化远端,而非本地。这使得 RisingWave 用户无需担心内部状态大小问题。为了实现性能最优,RisingWave 只在本地实例中做状态缓存。与此同时,RisingWave 在多流 join 等复杂场景下做了大量优化,尤其是在状态管理方面使用了更精细的管理模式,使系统保持高效与稳定。在生产场景下,RisingWave 能够很好的处理 10-20 个(甚至更多)流的 join。
瞬时动态扩缩容
在多数现有流处理中,动态扩缩容支持很弱。究其原因,主要是因为这些系统都采用了存算耦合的架构:内部状态存储与计算高度绑定。这导致了其无法平滑实现动态扩缩容。
RisingWave 采用了存算分离架构,使用远端对象存储持久化计算内部状态,而计算并不绑定内部状态。这使得动态扩缩容基本可以在秒级完成。
瞬时故障恢复
流计算系统定期保存检查点(checkpoints)。当故障发生时,系统只需要从最近的检查点开始重新进行计算。重算时间,也就是系统恢复时间,与检查点间隔正相关。多数现有流处理系统的检查点间隔在1分钟以上,而在实际生产环境上,不少将检查点配置在3分钟、5分钟、甚至10分钟(以上)。这是因为这些系统的检查点间隔会影响性能:检查点间隔过小会导致性能大幅下降。当检查点间隔过大时,便会导致当系统故障时,需要较长的恢复时间。而这种长时间的系统无可用在不少对延迟敏感的应用,如金融交易、监控、报警等,来说无法接受。
RisingWave 的内部状态管理方式使得 RisingWave 检查点频率与性能解耦。这也就意味着用户可以将检查点间隔设置的非常小,保证服务宕机时间最小化。默认情况下,RisingWave 的检查点间隔为10秒。
RisingWave 的不足
相比于 Apache Flink、Apache Spark Streaming 等流处理系统,RisingWave 不支持 Java、Python 等可编程接口。不少 Apache Flink、Apache Spark Streaming 的资深用户选择使用了 Java、Python 等接口来进行编程。如果已有代码逻辑过于复杂、无法使用 SQL 改写,那么可能就不适合使用 RisingWave。当然,RisingWave 支持 Python / Java 等语言的 UDF。因此,如果你的程序可以使用 UDF 来表示,那么还是可以选用 RisingWave 的。
尽管与 PostgreSQL 协议兼容,但 RisingWave 并不支持事务处理,因此不能在事务处理应用中平替 PostgreSQL。不少用户将 MySQL、PostgreSQL 等 OLTP 数据库与 RisingWave 组合使用:他们使用 OLTP 数据库做事务处理,然后使用 RisingWave 消费数据库的 CDC,在 RisingWave 内部做流计算。
RisingWave 底层存储为行存,适合支持高并发点查。但是,RisingWave 不适合做分析型随机查询。为支持分析型随机查询,用户还需将数据导入到实时分析数据库中进行操作。不少用户将 RisingWave 与 ClickHouse、Apache Doris 等实时分析数据库组合使用:他们使用 RisingWave 做流计算,同时使用实时分析数据库进行分析型随机查询。
RisingWave 使用场景
RisingWave 的主要使用场景包括了监控、报警、实时动态报表、流式 ETL、机器学习特征工程等。其已经运用到金融交易、制造业、新媒体、物流等领域。